
สมมุติให้ระบบฐานข้อมูลของมหาวิทยาลัยแห่งหนึ่งประกอบด้วยตารางข้อมูล 4 ตาราง และแอตทริบิวต์ต่าง ๆ ดังนี้
· ตารางนักศึกษา STUDENT (Std #, Std_Name)
· ตารางลงทะเบียนREGISTRATION (Std#, Course#)
· ตารางเกรด GRADE (Std#, Course#, Grade)
· ตารางวิชา COURSE (Course#, Course_Name, Instructor)
โดยในแต่ละตารางจะมีจำนวนข้อมูลดังนี้
· ตาราง STUDENT มีข้อมูลนักศึกษาจำนวน 40,000 แถว
· ตาราง REGISTRATION มีข้อมูล ตามจำนวนที่นักศึกษาลงทะเบียนเรียน แต่ไม่ใช่นักศึกษาทั้งหมด ในตัวอย่างนี้จะสมมุติว่า มีวิชาที่นักศึกษาต้องลงทะเบียนทั้งหมด 10 วิชา ต่อปี จะมีจำนวนข้อมูลทั้งหมดประมาณ 400,000 แถว
· ตาราง GRADE ถ้าสมมุติให้มีข้อมูลเฉลี่ย 10 วิชา ต่อนักศึกษา 1 คน จะมีข้อมูลทั้งหมด 400,000 แถว
· ตาราง COURSE มีข้อมูลวิชาบรรจุอยู่ 5,000 วิชา
ถ้าต้องการหารายชื่อนักศึกษาที่ลงทะเบียนในวิชา (Couse#) ที่เรียงลำดับอยู่หหลังวิชา COMP300 จากโจทย์ข้างต้นในภาษา SQL ผู้ใช้สามารถเลือกใช้คำสั่งได้หลายคำสั่งดังนี้คือ
คำสั่งที่ 1
select Std_Name, Course_Name
from STUDENT, REGISTRATION, COURSE
where STUDENT.Std# = REGISTRATION.Std# and
COURSE.Course# = REGISTRATION.Course# and
REGISTRATION.Course# > COMP300
คำสั่งที่ 2
select Std_Name, cl.Course_Name
from STUDENT, REGISTRATION, COURSE c1
where STUDENT.Std# = REGISTRATION.Std# and
REGISTRATION.course# in
(select c2.Course#
from COURSE c2
where c2.Course# > COMP300 and
cl.Course# = c2.Course#)
คำสั่งที่ 3
select Std_Name, cl.Course_Name
from STUDENT, COURSE c1
where STUDENT.Std# in
(Select REGISTRATION.Std#
from REGISTRATION
where REGISTRATION.course# in
(select c2.Course#
from COURSE c2
where c2.Course# > COMP300 and
cl.Course# = c2.Course#))
จากภาษา SQL ทั้ง 3 คำสั่งนี้เมื่อผ่านส่วนตรวจสอบภาษา (parser) ที่อยู่ในตัวประมวลผลสอบถามแล้วจะได้รูปแบบของพีชคณิตแบบสัมพันธ์ (relational algebra) ดังนี้
คำสั่งที่ 1
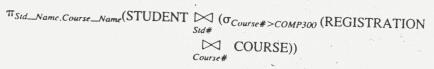
คำสั่งที่ 2
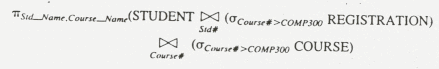
คำสั่งที่ 3
จากคำสั่งทั้ง 3 คำสั่งนี้จะทำการเปรียบเทียบว่าคำสั่งใดที่ทำการประมวลผลโดยการดึงข้อมูลจากฐานข้อมูลและขนาดของข้อมูลที่ได้ในแต่ละขั้นตอนในการประมวลผลน้อยที่สุด
จากคำสั่งที่ 1 จะมีการดึงข้อมูลและการประมวลผลข้อมูลได้ตามตารางที่ 8.3.2.1 มีขั้นตอนดังนี้
ตารางที่
8.3.2.1
ข้อมูลการประมวลผลในแต่ละขึ้นตอนของคำสั่งที่
1![]()
|
Operation |
Processing cost if relations |
Estimated size of |
|
|
Not sorted |
sorted |
result |
|
|
Join of STUDENT and REGISTRATION |
40,000 * 400,000 |
40,000 + 400,000 |
400,000 tuples |
|
Join of this result with COURSE |
5,000 * 400,000 |
5,000 + 400,000 |
400,000 tuples |
|
Selection from result of Course# > COMP300 |
400,000 |
400,000 |
40,000 tuples |
|
Projection on Std_Name, Course_Name |
40,000 |
40,000 |
40,000 tuples |
ขั้นที่ 1 เป็นการจอยน์ (join) ตาราง STUDENT กับตาราง REGISTRATION ซึ่งในตาราง STUDENT จะมีข้อมูลอยู่ 40,000 แถว และตาราง REGISTRATION มีข้อมูล 400,000 แถว เมื่อจอยน์กันแล้วจะทำให้ได้ผลลัพธ์ของการประมวลผลออกมาประมาณ 400,000 แถว ครั้ง ถ้าในกรณีที่ข้อมูลนั้นไม่ได้จัดเรียง (not sorted) ผลลัพธ์ที่ได้นี้จะต้องประมวลผลถึง 40,000 *1 400,000 ครั้ง แต่ถ้าข้อมูลนั้นถูกจัดเรียง (sorted) ก็จะประมวลผลเพียง 40,000 + 400,000 ครั้ง
ขั้นที่ 2 เป็นการจอยน์ (join) ระหว่างผลลัพธ์ที่ได้จากขั้นที่ 1 กับจำนวนแถวที่อยู่ในตาราง COURSE ซึ่งในกรณีที่ไม่มีการจัดเรียงข้อมูลจะทำให้ต้องประมวลผลถึง 5,000 * 400,000 ครั้ง ถ้ามีการจัดเรียงข้อมูลจะประมวลผลเพียง 5,000 + 400,000ครั้ง ซึ่งจะได้ผลลัพธ์ในขั้นตอนนี้ประมาณ 400,000 แถว
ขั้นตอนที่ 3 จากผลลัพธ์ที่ได้ในขั้นที่ 2 จะทำการเลือกวิชาที่มีลำดับมากกว่า COMP300 โดยในการเลือกนี้จะ ถ้าเราสมมุติว่าวิชาที่มากกว่า COMP300 จะทำการประมวลผลโดยการเปรียบเทียบเป็นจำนวน 400,000 ครั้ง ซึ่งจะได้ผลลัพธ์ของการประมวลผลในขั้นตอนนี้ประมาณ 40,000 แถว
ขั้นที่ 4 เป็นการจัดกลุ่ม (projection) ของ Std_Name และ Course_Name ซึ่งจะทำการประมวลผลทั้งหมด 40,000 ครั้งและได้ผลลัพธ์ออกมา 40,000 แถว
จากคำสั่งที่ 2 เมื่อพิจารณาการดึงข้อมูลและการประมวลผลข้อมูลตามตารางที่ 8.3.2.2 ทีมีการประมวลผลดังนี้
ตารางที่ 8.3.2.2 ข้อมูลการประมวลผลในแต่ละขั้นตอนของคำสั่งที่ 2
![]()
|
Operation |
Processing cost if relations |
Estimated size of |
|
|
Not sorted |
sorted |
result |
|
|
Join of REGISTRATION and COURSE |
5,000 * 400,000 |
5,000 + 400,000 |
400,000 tuples |
|
Selection from result of Course# > COMP300 |
400,000 |
400,000 |
40,000 tuples |
|
Join of STUDENT and result above |
40,000 * 40,000 |
40,000 + 40,000 |
40,000 tuples |
|
Projection on Std_Name, Course_Name |
40,000 |
40,000 |
40,000 tuples |
ขั้นที่ 1 เป็นการจอยน์ระหว่างตาราง REGISTRATION และตาราง COURSE โดยในกรณีที่ข้อมูลไม่ได้จัดเรียงจะต้องประมวลผลทั้งหมด 5,000 * 400,000 ครั้ง ถ้าข้อมูลจัดเรียงลำดับจะประมวลผลทั้งหมด 5,000 + 400,000 ครั้ง ผลลัพธ์ที่ได้จากขั้นที่ 1 นี้ จะมีประมาณ 400,000 แถว
ขั้นที่ 2 จากผลลัพธ์ที่ได้ในขั้นที่ 1 จะทำการเลือกวิชาที่มากกว่า COMP300 ซึ่งจะต้องประมวลผลถึง 400,000 ครั้ง จะได้ผลลัพธ์ออกมาประมาณ 40,000 แถว
ขั้นที่ 3 เป็นการจอยน์ภายในตาราง STUDENT กับผลลัพธ์ที่ได้ในขั้นที่ 2 เพื่อหา Std# โดยในกรณีที่ข้อมูลไม่ได้จัดเรียงจะประมวลผลทั้งหมด 40,000 * 40,000ครั้ง และจะประมวลผลทั้งหมด 40,000 + 40,000 ครั้ง ในกรณีที่ข้อมูลจัดเรียง ซึ่งจะได้ผลลัพธ์ออกมาประมาณ 40,000 แถว
ขั้นที่ 4 เป็นการจัดกลุ่ม (projection) ของ Std_Name และ Course_Name จากผลลัพธ์ที่ได้ในขั้นที่ 2 ซึ่งมีการประมวลทั้งหมด 40,000 ครั้ง และได้ผลลัพธ์ของการประมวลผลประมาณ 40,000 แถว
จากคำสั่งที่ 3 จะเห็นว่าจะใช้คำสั่งในการเลือก (selection) ก่อนที่จะจอยน์ (joins) ซึ่งเมื่อพิจารณาการดึงข้อมูลและการประมวลผลข้อมูลจะได้ ดังตารางที่ 8.3.2.3
ตารางที่ 8.3.2.3 แสดงข้อมูลการประมวลผลในแต่ละขั้นตอนของคำสั่งที่ 3
![]()
|
Operation |
Processing cost if relations |
Estimated size of |
|
|
Not sorted |
sorted |
result |
|
|
Selection from COURSE Course# > COMP300 |
5,000 |
5,000 |
500 tuples |
|
Selection from REGISTRATION Course# > COMP300 |
400,000 |
400,000 |
40,000 tuples |
|
Join of selected tuples from COURSE and REGISTRATION with result above |
500 * 40,000 |
500 + 40,000 |
40,000 tuples |
|
Join of STUDENT with result above |
40,000 * 40,000 |
40,000 + 40,000 |
40,000 tuples |
|
Projection on Std_Name, Course_Name |
40,000 |
40,000 |
40,000 tuples |
ขั้นที่ 1 เลือก(selection)จากตาราง COURSE โดยรหัสวิชา (Course#) ที่มากกว่า COMP300 ผลของคำสั่งนี้จะทำให้มีการประมวลผล 5,000 ครั้ง และจะได้ผลลัพธ์ออกมาประมาณ 500 แถว
ขั้นที่ 2 เลือกจากตาราง REGITRATION โดยรหัสวิชา (Course#) ที่มากกว่า COMP300 ผลของคำสั่งนี้จะทำให้มีการประมวลผลทั้งหมด 400,000 ครั้ง ได้ผลลัพธ์ประมาณ 400,000 แถว
ขั้นที่ 3 เป็นการจอยน์ระหว่างผลลัพธ์ที่ได้ในขั้นที่ 1 กับผลลัพธ์ที่ได้จากการเลือกรหัสวิชาของขั้นที่ 2 จะทำให้ต้องประมวลผลถึง 500 * 40,000 ครั้งในกรณีที่ไม่ได้เรียงข้อมูลและจำนวน 500 + 40,000 กรณีที่จัดเรียงข้อมูลและจะได้ผลลัพธ์ออกมาประมาณ 40,000 แถว
ขั้นที่ 4 ผลลัพธ์ที่ได้จากขั้นที่ 3 จะจอยน์กับตาราง STUDENT ในกรณีที่ไม่ได้จัดเรียงข้อมูล จะทำต้องมีการประมวลผลทั้งหมด 40,000 * 40,000 ครั้งหรือในกรณีที่จัดเรียงข้อมูลจะประมวลผลทั้งหมด 40,000 + 40,000 ครั้งจะได้ผลลัพธ์ประมาณ 40,000 แถว
ขั้นที่ 5 ผลลัพธ์ที่ได้จากขั้น 4 จะจัดกลุ่มของ Std_Name และ Course_Name ซึ่งจะต้องประมวลผลทั้งหมด 40,000 ครั้ง จะได้ผลลัพธ์ออกมาประมาณ 40,000 ครั้ง
สรุปว่าจากคำสั่งทั้ง 3 คำสั่ง ผู้ใช้ควรเลือกคำสั่งในการประมวลผลคือคำสั่งที่ 3 เพราะจะมีจำนวนของการประมวลผลและผลลัพธ์ในแต่ละขั้นตอนน้อยกว่าคำสั่งอื่น ๆ การเลือกคำสั่งที่ 3 เข้าประมวลผลถือเป็นการทำออพติไมเซชั่น (optimisation) ที่ผู้ใช้เป็นผู้กระทำโดยการเลือกคำสั่งเข้ามาประมวลผล แต่ในระบบการจัดการฐานข้อมูลนั้นเมื่อผู้ใช้ป้อนคำสั่งภาษาสอบถามเข้าไปแล้ว ระบบจะนำคำสั่งนั้นไปประมวลผลซึ่งในขั้นตอนของการประมวลผลนั้นจะมีการการทำออพติไมเซชั่น (optimisation) ระบบจัดการฐานข้อมูลใช้เทคนิคต่าง ๆ ในการประมวลผลโดยคำนึงถึงการดึงข้อมูลมาประมวลผลให้น้อยที่สุดและใช้เวลาน้อยในการประมวลผลน้อยที่สุด
จากตัวอย่างที่กล่าวมาทั้งหมดจะเห็นว่าการหาแผนการเข้าถึงข้อมูล (access plan) หรือการทำออพติไมเซชั่น (optimisation) สามารถทำได้จากผู้ใช้โดยตรงก่อน โดยผู้ใช้จะเป็นเหมือนออฟติไมเซอร์ได้โดยเลือกคำสั่งที่มีการประมวลผลข้อมูลน้อย เพื่อประหยัดเวลาในการประมวลผล ต่อจากนั้นระบบจัดการฐานข้อมูลจะนำคำสั่งที่ผู้ใช้เลือกแล้วมาทำออพติไมเซชั่น (optimisation) ชันอีกครั้งโดยใช้เทคนิคและวิธีการต่าง ๆ ที่ระบบการจัดการฐานข้อมูลนั้น ๆ มีอยู่ เช่น เทคนิคการซอร์ตและการเมอร์จ (sorting and merge method), เทคนิคดีคอมโพสิชั่น (decomposition method) และเทคนิคโอเปอร์เรเตอร์กราฟ (operator graph) ซึ่งเทคนิคต่างๆ เหล่านี้จะทำให้ใช้เวลาในการประมวลผลน้อย