![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
|
|
|
|
|
 |
|
|
การเข้าถึงข้อมูลในระบบแบบกระจายโดยปกติแล้วจะดำเนินการผ่านทรานแซกชัน ซึ่งจะต้องรักษาคุณสมบัติ ACID ซึ่งในการทำทรานแซกชันมีอยู่สองประเภทคือ local ทรานแซกชัน ซึ่งจะดำเนินการกับข้อมูลในฐานข้อมูลที่ local เท่านั้น และอีกประเภทหนึ่งคือ global ทรานแซกชัน ซึ่งจะทำการเข้าถึงข้อมูลและปรับปรุงข้อมูลในหลาย ๆ ฐานข้อมูล ในกรณีของ global ทรานแซกชัน การรักษาคุณสมบัติ ACID ของการทำทรานแซกชันแบบกระจายจะมีการดำเนินการที่ซับซ้อนมากขึ้น เนื่องจากแต่ละไซต์จะมีส่วนร่วมในการทำทรานแซกชัน ซึ่งความล้มเหลวที่เกิดขึ้นในไซต์เหล่านี้ หรือความล้มเหลวจากการสื่อสารกันระหว่างไซต์ อาจทำให้การทำทรานแซกชันผิดพลาดได้
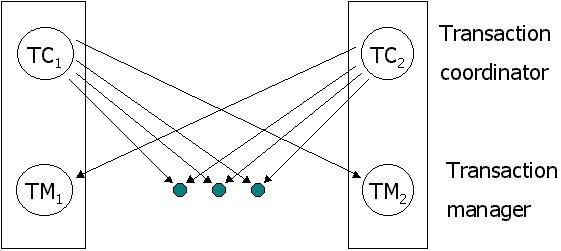
ในแต่ละไซต์จะมีตัวจัดการทรานแซกชัน(local transaction manager) เป็นของตนเอง ซึ่งทำหน้าที่ควบคุมให้การทำทรานแซกชันให้มีคุณสมบัติ ACID โดยที่ตัวจัดการทรานแซกชันแต่ละตัวก็จะร่วมกันในการทำ global transaction เพื่อความเข้าใจมากยิ่งขึ้น เราจะกำหนดโมเดลของระบบทรานแซกชัน โดยในแต่ละไซต์ประกอบไปด้วยระบบย่อยสองระบบคือ - ตัวจัดการทรานแซกชัน(transaction manager) จะทำหน้าที่คอยควบคุมดูแลการดำเนินการของทรานแซกชันต่างๆ ที่มีการเข้าถึงข้อมูลในไซต์ของตนเอง แต่ละทรานแซกชันเป็นได้ทั้ง local ทรานแซกชัน หรือเป็นส่วนหนึ่งของ global ทรานแซกชันก็ได้ - ตัวประสานงานทรานแซกชัน(transaction coordinator) ทำหน้าที่ประสานการทำงานของทรานแซกชันต่าง ๆ ทั้ง local และ global ภาพรวมของระบบสามารถแสดงได้ดังรูป
รูปที่ 13.7 แสดงโครงสร้างของระบบ โดย transaction manager จะมีหน้าที่ดังนี้ - การจัดการกับ log เพื่อจุดประสงค์ในการฟื้นคืนสภาพข้อมูล - มีส่วนร่วมในการทำ concurrency control กับไซต์อื่นเพื่อร่วมทำ concurrent execution ของทรานแซกชันในไซต์ของตนเอง transaction coordinator มีหน้าที่ดังนี้ - เริ่มต้นทำทรานแซกชัน - แบ่งทรานแซกชันออกเป็นทรานแซกชันย่อย และส่งไปยังไซต์ที่เหมาะสมเพื่อ - ประสานการดำเนินการของทรานแซกชันว่า ผลของการทำทรานแซกชันนั้น ทำสำเร็จในทุก ๆ ไซต์ หรือยกเลิกในทุก ๆ ไซต์
เพื่อให้การทำทรานแซกชันบนระบบฐานข้อมูลแบบกระจายมีคุณสมบัติ Atomicity คือทรานแซกชัน T ต้อง commit ในทุก ๆ ไซต์ หรือยกเลิกการทำทรานแซกชันในทุก ๆ ไซต์ ตัวประสานงานทรานแซกชันของทรานแซกชัน T ต้องมีการทำ commit protocol วิธีการของ commit protocol มีการใช้งานกันอย่างแพร่หลายคือ two-phase commit protocol(2PC) และ three-phase commit protocol(3PC) ซึ่งจะช่วยหลีกเลี่ยงข้อเสียของ 2PC แต่การดำเนินการจะมีความซับซ้อนมากกว่า
ให้ T เป็นทรานแซกชันเริ่มต้นที่ไซต์ Si และให้ ตัวประสานงานทรานแซกชันที่ไซต์ Si เป็น Ci
เมื่อทรานแซกชัน T ได้ทำการประมวลผลเสร็จสิ้น นั่นคือ ทุก ๆ ไซต์ที่ทรานแซกชัน T ได้ประมวลผลได้แจ้งกลับมาที่ Ci ว่า ได้ทำทรานแซกชัน T เสร็จเรียบร้อยแล้ว ตัวประงานงานทรานแซกชัน Ci จะเริ่มทำโปรโตคอล 2PC
Ci เพิ่มเรคอร์ด <prepare T> ลงไปใน log ไฟล์บน stable storage จากนั้นก็จะส่งสัญญาณ prepare T ไปให้กับทุก ๆ ไซต์ที่ประมวลผลทรานแซกชัน T เมื่อไซต์อื่น ๆ ได้รับสัญญาน ตัวจัดการทรานแซกชันจะต้องตอบกลับไปหาตัวประสานงานทรานแซกชันว่าจะทำการ commit ทรานแซกชันได้หรือไม่ ถ้าไม่ได้จะเพิ่มเรคอร์ด <no T> ลงไปใน log ไฟล์และส่งสัญญาณ abort T กลับไปที่ Ci ถ้าได้จะเพิ่มเรคอร์ด <ready T> ลงไปใน log ไฟล์ และตัวจัดการทรานแซกชันจะส่งสัญญาณ ready T กลับไปที่ Ci
ทรานแซกชัน T ทรานแซกชัน T จะ commit ได้ก็ต่อเมื่อได้รับสัญญาณ ready T จากทุก ๆ ไซต์ที่มีส่วนร่วมในการทำทรานแซกชัน นอกเหนือจากนั้นทรานแซกชัน T จะต้องถูกยกเลิก ซึ่งก็จะต้องทำการเพิ่มเรคอร์ด <commit T> หรือ <abort T> ลงไปใน log ไฟล์ ถ้าทรานแซกชัน T สามารถ commit ได้ หรือ ยกเลิกการทำทรานแซกชัน จากนั้น ตัวประสานงานทรานแซกชันก็จะส่งสัญญาณ commit T หรือ abort T ไปให้กับทุกๆ ไซต์ที่ร่วมกันทำทรานแซกชัน เมื่อแต่ละไซต์ได้รับสัญญาณก็จะทำการบันทึกเรคอร์ดนี้ลงไปใน log ไฟล์ จะเห็นว่าสัญญาณ ready T มีความสำคัญมาก เนื่องจากไซต์ต่าง ๆ ที่ทำทรานแซกชัน T จะต้องส่งสัญญาณ ready T กลับไปให้ตัวประสานงานทรานแซกชัน เพื่อบอกกับตัวประสานงานทรานแซกชันว่าพร้อมที่จะ commit แล้วซึ่งสัญญาณนี้จะมีผลต่อการทำ commit หรือ abort ของทรานแซกชัน จากลักษณะดังกล่าวอาจเป็นไปได้ว่าเมื่อไซต์หนึ่งได้ทำการส่งสัญญาณ ready T ไปให้ตัวประสานงานทรานแซกชันแล้ว อาจเกิดความล้มเหลวของไซต์ได้ ซึ่งจากโปรโตคอล 2PC เมื่อตัวประสานงานทรานแซกชันได้รับสัญญาณ ready T หรือ abort T ครบ ก็จะส่งสัญญาณ commit T หรือ abort T ไปให้กับไซต์ที่ร่วมทำทรานแซกชันเท่านั้น โดยไม่ได้สนใจว่าไซต์ต่าง ๆ เหล่านั้นสามารถ commit หรือ abort ตามสัญญาณที่ส่งไป ได้หรือไม่ ดังนั้นในการดำเนินการโปรโตคอล 2PC จะมีการส่งสัญญาณ acknowledge T กลับมาที่ตัวประสานงานทรานแซกชันเพื่อเป็นการบอกว่าได้ดำเนินการ ในระยะที่สองเสร็จเรียบร้อยแล้ว เมื่อตัวประสานงานทรานแซกชันได้รับ acknowledge T ครบจากทุก ๆ ไซต์ ก็จะเพิ่มเรคอร์ด <complete T> เข้าไปใน log ไฟล์
ความล้มเหลวในการทำทรานแซกชันมีอยู่หลายกรณี ซึ่งจะมีการจัดการกับความล้มเหลวต่าง ๆ เหล่านั้นดังนี้ 1. Failure of participating site ถ้าตัวประสานงานทรานแซกชันตรวจพบว่า มีไซต์หนึ่งเกิดล้มเหลวขึ้นมา ก็ต้องพิจารณาว่า ไซต์นั้นเกิดความล้มเหลาก่อนการส่งสัญญาณ ready T หรือไม่ ถ้าเกิดความล้มเหลวก่อน ตัวประสานงานทรานแซกชันจะถือว่าไซต์นั้นส่งสัญญาณ abort T กลับมาให้ แต่ถ้าไซต์นั้นล้มเหลวหลังจากที่ได้ส่งสัญญาณ การดำเนินการโปรโตคอล 2PC ก็จะดำเนินการไปตามปกติโดยไม่สนใจไซต์ที่ล้มเหลว เมื่อไซต์ที่ร่วมทำทรานแซกชัน Sk ทำการ ฟืนคืนสภาพข้อมูล จากความล้มเหลวของไซต์ จะต้องกมีการตรวจสอบ log ไฟล์ เพื่อกำหนดว่าจะต้องทำอย่างไรกับทรานแซกชันที่ยังทำไม่เสร็จ กำหนดให้ T เป็นทรานแซกชันที่ยังทำไม่เสร็จ เราจะต้องพิจารณากรณีต่าง ๆ ต่อไปนี้ - ถ้าใน log ไฟล์ มีเรคอร์ด <commit T> ให้ทำการ redo(T) - ถ้าใน log ไฟล์ มีเรคอร์ด <abort T> ให้ทำการ undo(T) - ถ้าใน log ไฟล์ มีเรคอร์ด <ready T> ในกรณีนี้ต้องติดต่อกับ Ci ว่าได้ส่งสัญญาณอะไรมาให้ ถ้าพบว่าทรานแซกชันได้ทำการ commit ทรานแซกชัน T ก็จะทำการ redo(T) และจะทำ undo(T) ถ้าพบว่าได้ทำการ abort ทรานแซกชัน แต่ถ้าไม่สามารถติดต่อกับ Ci ได้ ไซต์ Sk ก็จะต้องพยายามตรวจสอบว่าทรานแซกชันได้ทำ commit หรือ abort จากไซต์อื่น ๆ ทุกไซต์ โดยการส่งสัญญาณ query-status T ไปให้กับทุก ๆ ไซต์ เมื่อไซต์ได้รับสัญญาณ query-status T ก็จะทำการตรวจสอบกับ log ไฟล์ว่าได้ทำ commit หรือ abort กับ ทรานแซกชัน T - log ไฟล์ ไม่ปรากฏเรคอร์ด(abort, commit, ready) อะไรเลยที่เกี่ยวข้องกับทรานแซกชัน T หมายความว่าไซต์ได้เกิดความล้มเหลวก่อนที่จะส่งสัญญาณ ready T กลับไปให้ตัวประสานงานทรานแซกชัน ทำให้ทรานแซกชันต้อง abort ดังนั้น Sk ต้องทำ undo(T) 2. Failure of coordinator ถ้าตัวประสานงานทรานแซกชันล้มเหลวในระหว่างที่กำลังทำทรานแซกชัน ไซต์ที่ร่วมกันทำทรานแซกชัน ต้องคอยให้ตัวประสานงานทรานแซกชันกลับมาเริ่มต้นทำงานใหม่แล้วจึงค่อยดำเนินการต่อ - ถ้าใน log ไฟล์มีเรคอร์ด <commit T> ดังนั้นทรานแซกชัน ต้องทำการ commit - ถ้าใน log ไฟล์มีเรคอร์ด <abort T> ดังนั้นทรานแซกชัน ต้องถูก abort - ถ้าในบางไซต์ไม่มีเรคอร์ด <ready T> ใน log ไฟล์ ดังนั้นจะไม่สามารถทำการ commit ได้ เนื่องจากไม่ได้ส่งสัญญาณ ready T กลับไปให้ตัวประสานงานทรานแซกชัน ดังนั้นตัวประสานงานทรานแซกชันก็จะต้องทำการ abort ทรานแซกชัน อยู่แล้ว ซึ่งในกรณีนี้ไม่จำเป็นต้องรอให้ Ci กลับมาเริ่มต้นทำงานใหม่อีกครั้ง สามารถที่จะ abort ได้ทันที ถ้าในทุก ๆ ไซต์มีเรคอร์ด <ready T> แต่ไม่มีอะไรต่อจากนั้นเช่น abort หรือ commit ทำให้ไม่สามารถตัดสินใจได้ว่าจะต้องทำอะไร ดังนั้นไซต์ต่างๆ ต้องคอย Ci กลับให้มาเริ่มต้นทำงานใหม่ แล้วค่อยดำเนินทรานแซกชันต่อไป และในขณะที่คอยก็ต้องใช้ทรัพยากรของระบบด้วย
3PC ถูกออกแบบมาเพื่อหลีกเลี่ยงปัญหา Blocking ที่เกิดขึ้นใน 2PC โดยโปรโตคอล 3PC จะมีข้อกำหนดดังต่อไปนี้ 1. จะต้องไม่เกิดกรณี network partition 2. ไซต์ที่ร่วมในการทำทรานแซกชันทั้งหมด k ไซต์ สามารถล้มเหลวได้ในขณะที่กำลังทำ 3PC โดยที่ k เป็นพารามิเตอร์ที่บ่งบอกถึงความยืดหยุ่นของโปรโตคอลในไซต์ที่ล้มเหลวอย่างน้อย k+1 ไซต์
กำหนดให้ T เป็นทรานแซกชันที่เกิดขั้นที่ไซต์ Si และกำหนดให้ตัวประสานงานทรานแซกชันเป็น Ci Phase 1 ขั้นตอนนี้มีวิธีการเหมือนกับขั้นตอนที่ 1 ในโปรโตคอล 2 PC ทุกประการ Phase 2 ถ้า Ci ได้รับสัญญาณ abort T จากไซต์อื่น หรือถ้า Ci ไม่ได้รับสัญญาณตอบกลับภายในระยะเวลาที่กำหนด แล้ว Ci ก็จะทำการ abort T การตัดสินใจยกเลิกทรานแซกชันนี้ทำในลักษณะเดียวกันกับ โปรโตคอบ 2PC และถ้า Ci ได้รับสัญญาณ ready T จากทุก ๆ ไซต์ Ci จะทำการสร้างขั้นตอนการเตรียมตัดสินใจเพื่อ precommit T การทำ precommit แตกต่างจากการทำ commit คือ ทรานแซกชัน T ยังสามารถที่จะยกเลิกได้ตราบใดที่เรายังไม่ได้ Commit จริง ๆ การทำ precommit จะยอมให้ตัวประสานงานทรานแซกชันบอกกับไซต์ที่ร่วมประมวลผล ว่าตอนนี้ทุก ๆ ไซต์พร้อมที่จะดำเนินการในขั้นตอนไป โดย Ci จะทำการเพิ่มเรคอร์ด <precommit T> เข้าไปใน log ไฟล์ จากนั้น Ci จะส่งสัญญาณ precommit T ไปให้ทุก ๆ ไซต์ เมื่อไซต์ต่าง ๆ ได้รับสัญญาณ(ทั้ง abort T หรือ precommit T) จากตัวประสานงานทรานแซกชัน ก็จะทำการเพิ่มเรคอร์ดเข้าไปใน log ไฟล์ และส่งสัญญาณ acknowledge T กลับไปให้ตัวประสานงานทรานแซกชัน Phase 3 ขั้นตอนนี้จะทำก็ต่อเมื่อการทำ precommit ในขั้นตอนที่ 2 สำเร็จ นั่นคือหลังจากที่สัญญาณ precommit T ได้ถูกส่งไปยังทุก ๆ ไซต์ และตัวประสานงานทรานแซกชันต้องคอยจนกระทั่งได้รับสัญญาณ acknowledge T เป็นจำนวนอย่างน้อย k ไซต์ จากนั้นก็จะเข้าสู่ขั้นตอนการ commit โดยการเพิ่ม <commit T> เข้าไปใน log ไฟล์ จากนั้นก็จะส่งสัญญาณ commit T ไปให้กับไซต์ทุก ๆ ไซต์ เมื่อไซต์ต่างๆ ได้รับสัญญาณก็จะทำการเก็บข้อมูลลงไปใน log ไฟล์ ตรงกันข้ามกับโปรโตคอล 2PC ซึ่งตัวประสานงานทรานแซกชันสามารถ abort ทรานแซกชัน T ณ เวลาใด ๆ ก่อนที่จะมีการส่งสัญญาณ commit T ซึ่งสัญญาณ precommit T ของโปรโตคอล 3PC จะเป็นสิ่งที่ใช้บอกตัวประสานงานทรานแซกชันว่าให้ดำเนินอะไรต่อไปตามคำสั่งของไซต์อื่น ๆ เพื่อทำการ commit T ในการดำเนินการของโปรโตคอล 3PC ไซต์หนึ่ง ๆ ส่งสัญญาณ ack T ไปให้ตัวประสานงานทรานแซกชัน เมื่อตัวประสานงานทรานแซกชันได้รับสัญญาณ ack T ครบทุกไซต์ ก็จะทำการเพิ่มเรคอร์ด <commit T> เข้าไปใน log ไฟล์
ความล้มเหลวที่อาจจะเกิดขึ้นสามารถจำแนกได้ดังนี้ 1. Failure of a participating site ถ้าตัวประสานงานทรานแซกชัน Ci ตรวจพบว่ามีไซต์บางไซต์ล้มเหลว การดำเนินการก็จะเหมือนกับ 2PC ถ้าไซต์นั้นล้มเหลวก่อนที่จะมีการส่งสัญญาณ ready T กลับไปให้ Ci ก็จะถือว่าได้มีการส่งสัญญาณ abort T กลับไป นอกนั้นก็จะดำเนินการโปรโตคอล commit ต่อไปโดยไม่สนใจว่าไซต์จะล้มเหลวหรือไม่ เมื่อไซต์ที่ร่วมทำทรานแซกชัน Sj ได้ทำการฟื้นคืนสภาพกลับมา จะต้องมีการตรวจสอบ log ไฟล์ เพื่อจะได้ดำเนินการทรานแซกชันต่อไป ให้ T เป็นทรานแซกชัน และจะพิจารณาในแต่ละกรณีต่อไปนี้ - log ไฟล์ มีเรคอร์ด <commit T> ในกรณีนี้ให้ทำ redo(T) - log ไฟล์ มีเรคอร์ด <abort T> ในกรณีนี้ให้ทำ undo(T) - log ไฟล์ มีเรคอร์ด <ready T> แต่ไม่มี <abort T> หรือ <precommit T> ในกรณีนี้ต้องติดต่อไปยังตัวประสานงานทรานแซกชัน ถ้า Ci ตอบกลับมาว่าให้ยกเลิกทรานแซกชัน ก็ให้ทำ undo(T) และถ้า Ci ตอบกลับมาว่า precommit T ไซต์ก็จะทำการบันทึกเรคอร์ด precommit T เข้าไปใน log ไฟล์ และจะดำเนินการทำทรานแซกชันต่อไป โดยการส่งสัญญาณ acknowledge T กลับไปให้ตัวประสานงานทรานแซกชัน และถ้า Ci ตอบกลับมาว่าให้ commit ทรานแซกชัน ก็ให้ทำ redo(T) - log ไฟล์ มีเรคอร์ด <precommit T> แต่ไม่มี <abort T> หรือ <commit T> ในกรณีนี้ต้องติดต่อไปยังตัวประสานงานทรานแซกชัน ถ้า Ci ตอบกลับมาว่าให้ยกเลิกทรานแซกชันหรือ commit ไซต์ก็จะต้องทำ undo(T) หรือ redo(T) ตามลำดับ และถ้า Ci ตอบกลับมาว่ายังอยู่ในระหว่างการทำ precommit ไซต์ก็จะจะดำเนินการทำทรานแซกชันต่อไป และถ้า Ci ไม่สามารถตอบกลับภายในเวลาที่ได้กำหนดไว้ ก็จะถือว่า ตัวประสานงานทรานแซกชันล้มเหลว ก็ให้ดำเนินการโปรโตคอล coordinator-failure 2. Failure of the coordinator เมื่อไซต์ที่ร่วมทำทรานแซกชัน ไม่ได้รับการตอบกลับจากตัวประสานงาน ทรานแซกชัน ไม่ว่าด้วยเหตุผลใดก็ตาม จะต้องทำ coordinator-failure protocol ซึ่งโปรโตคอลนี้จะเป็นการเลือกตัวประสานงานทรานแซกชันใหม่ และเมื่อไซต์ที่เคยเป็นตัวประสานงานทรานแซกชันกลับมาทำงานใหม่ก็จะปฏิบัติตัวในฐานะของไซต์ที่ร่วททำทรานแซกชัน
โปรโตคอล coordinator-failure ถูกกระตุ้นให้เกิดขึ้นโดยไซต์ที่ไม่ได้รับการตอบสนองจากตัวประสานงาน ทรานแซกชัน ภายในระยะเวลาที่กำหนด ซึ่งมีขั้นตอนดังนี้ 1. ไซต์ที่ active ทำการเลือกตัวประสานงานทรานแซกชันใหม่ โดยใช้ election protocol 2. ตัวประสานงานทรานแซกชันใหม่ Cnew ส่งสัญญาณให้กับแต่ละไซต์เพื่อขอทราบสถานะของ local ทรานแซกชัน ของ T 3. แต่ละไซต์ที่ร่วมทำทรานแซกชัน รวมทั้ง Cnew ตรวจสอบสถานะของทรานแซกชันดังนี้ - สถานะ Committed ใน log ไฟล์จะมีเรคอร์ด <commit T> - สถานะ Aborted ใน log ไฟล์จะมีเรคอร์ด <abort T> - สถานะ Ready ใน log ไฟล์จะมีเฉพาะเรคอร์ด <ready T> แต่ไม่มีเรคอร์ด <abort T> หรือ <precommit T> - สถานะ Precommitted ใน log ไฟล์จะมีเรคอร์ด <precommit T> แต่ไม่มีเรคอร์ด <abort T> หรือ<commit T> - Not ready ใน log ไฟล์ ไม่มีทั้งเรคอร์ด <ready T> และ <abort T> แต่ละไซต์ที่ร่วมทำทรานแซกชันจะต้องส่งสถานะของทรานแซกชันให้กับ Cnew 4. Cnew จะทำการ commit หรือ abort ทรานแซกชัน T หรือเริ่มทำ 3PC protocol ใหม่ ก็ขึ้นอยู่กับ local status ที่ได้รับตอบกลับมาจากไซต์อื่นๆ - ถ้ามีอย่างน้อยหนึ่งไซต์ที่มี local status เป็น committed แล้ว ให้ Cnew ทำการ commit ทรานแซกชัน T - ถ้ามีอย่างน้อยหนึ่งไซต์ที่มี local status เป็น aborted แล้ว ให้ Cnew ยกเลิกการทำทรานแซกชัน T - ถ้าไม่มีไซต์ใดมี local status เป็น aborted และไม่มีไซต์ใดมี local status เป็น committed แต่มีอย่างน้อยหนึ่งไซต์ที่มี local status เป็น precommitted แล้ว ให้ Cnew ดำเนินการ 3PC ต่อ โดยการส่งสัญญาณ precommit ใหม่ นอกนั้นให้ Cnew ยกเลิกทรานแซกชัน T
ในกรณีที่ตัวประสานงานทรานแซกชันล้มเหลว ระบบสามารถทำงานต่อไปได้ โดยการกำหนดตัวประสานงานทรานแซกชันขึ้นมาใหม่โดยการสร้างตัวประสานงานทรานแซกชันสำรอง(backup coordinator)ซึ่งพร้อมที่จะทำหน้าที่เป็นตัวประสานงานทรานแซกชันทันที่ที่ตัวประสานงานทรานแซกชันล้มเหลว หรือจะเป็นวิธีการเลือกตัวประสานงานทรานแซกชันใหม่หลังจากที่ตัวประสานงานทรานแซกชันล้มเหลว - Backup Coordinator ตัวประสานงานทรานแซกชันสำรอง เป็นไซต์ ๆ หนึ่งซึ่ง เมื่อมีสัญญาณถูกส่งมาให้ตัวประสานงาน ทรานแซกชัน ก็จะถูกส่งให้ตัวประสานงานทรานแซกชันสำรองด้วย ตัวประสานงานทรานแซกชันสำรองจะทำหน้าที่ทุกอย่างเหมือนกับตัวประสานงานทรานแซกชันทุกอย่าง ยกเว้นแต่การดำเนินการต่างๆ จะไม่มีผลต่อไซต์อื่น ๆ เมื่อตัวประสานงานทรานแซกชันสำรองพบว่าตัวประสานงานทรานแซกชันปัจจุบันล้มเหลว มันก็จะเปลี่ยนตัวมันเป็นตัวประสานงานทรานแซกชันแทน ทำให้การประมวลผลทำได้อย่างต่อเนื่องไม่ติดขัด ข้อดีของแนวทางนี้คือ สามารถที่จะทำการประมวลผลต่อเนื่องได้ทันที แต่ข้อเสียก็คือจะต้องมีการทำกระบวนการทำสำเนาตลอดเวลา และจะต้องแน่ใจด้วยว่าข้อมูลต่างๆ ระหว่างตัวประสานงานทรานแซกชันและตัวประสานงานทรานแซกชันสำรองต้องสอดคล้องกันด้วย - Election Algorithm วิธีการนี้ต้องมีการกำหนดเลขเอกลักษณ์(identification number)ให้กับแต่ละไซต์ในระบบ ตัวอย่างเช่น เรากำหนดเลขเอกลักษณ์ของไซต์ Si เป็น i และกำหนดว่าตัวประสานงานทรานแซกชันจะอยู่ที่ไซต์ที่มีเลขเอกลักษณ์มากที่สุด ซึ่งจุดประสงค์ของวิธีการนี้คือเลือกไซต์ที่จะทำหน้าที่เป็นตัวประสานงานทรานแซกชันใหม่ ดังนั้นเมื่อตัวประสานงานทรานแซกชันเกิดล้มเหลวขึ้นมา วิธีการนี้ก็จะเลือกไซต์ที่มีเลขเอกลักษณ์มากที่สุด และเลขตัวนี้จะถูกส่งไปให้กับทุก ๆ ไซต์ในระบบ
ในหัวข้อนี้จะกล่าวถึงแนวทางในการควบคุมสภาวะการใช้งานพร้อมกันในสภาพแวดล้อมแบบกระจาย
โปรโตคอลการล๊อกข้อมูลที่ใช้กับฐานข้อมูลแบบรวมศูนย์ มีอยู่ด้วยกันหลายวิธี สามารถที่จะนำมาใช้กับฐานข้อมูลแบบกระจายได้ ซึ่งก็มีหลายแนวทางดังนี้ 1. Single-Lock-Manager Approach ในระบบจะมีตัวจัดการการล๊อก(lock manager)เพียงตัวเดียว ที่ไซต์ใดไซต์หนึ่ง การล๊อกและการปลดล๊อกจะต้องร้องขอมาที่ไซต์ Si เมื่อทรานแซกชันหนึ่งต้องการที่จะล๊อกข้อมูล ก็จะส่งความต้องการการล๊อกไปที่ไซต์ Si เมื่อตัวจัดการการล๊อกตรวจสอบว่าสามารถล๊อกได้ก็จะส่งสัญญาณกลับไปยังไซต์ที่ร้องขอการล๊อก ถ้าพบว่าล๊อกไม่ได้ก็จะให้คอยจนกว่าจะสามารถล๊อกได้ ข้อดี 1.1 จัดการการล๊อกได้ง่าย(Simple Implementation) ในการล๊อกวิธีนี้จะมีการจัดการอยู่สองอย่างคือ การจัดการเกี่ยวกับการร้องขอการล๊อก และการจัดการเกี่ยวกับการร้องขอการปลดล๊อกเท่านั้น 1.2 จัดการล๊อกตายได้ง่าย(Simple deadlock handling) เนื่องจากการล๊อกและการปลดล๊อก มีการดำเนินการที่ไซต์เดียว ก็สามารถที่จะนำวิธีการจัดการกับล๊อกตายที่ใช้กับระบบฐานข้อมูลแบบรวมศูนย์มาใช้ได้ทันที ข้อเสีย 1.1 เกิดปัญหาคอขวด(Bottleneck) เนื่องจากการร้องขอจากทุก ๆ ไซต์จะส่งมาที่ไซต์ Si เพียงไซต์เดียว 1.2 ไม่มีความมั่นคงของระบบ(Vulnerability) ถ้าไซต์ Si เกิดล้มเหลว ก็จะไม่สามารถควบคุมการทำงานพร้อม ๆ กันได้ การประมวลผลจะหยุดชะงัก หรือไม่ก็ต้องมีการเลือกไซต์ได้ไซต์หนึ่งให้มาทำหน้าที่เป็นตัวจัดการการล๊อก เพื่อให้การประมวลผลดำเนินต่อไป 2. Multiple Coordinators ถ้าพิจารณาถึงข้อดีและข้อเสียแล้ว multiple-coordinator ก็เป็นอีกแนวทางหนึ่งที่น่าสนใจ เนื่องจากตัวจัดการล๊อกจะอยู่ในแต่ละไซต์ ซึ่งจะจัดการกับการร้องขอการล๊อกและการร้องขอการปลดล๊อกของข้อมูลที่เก็บอยู่ภายในไซต์นั้น ซึ่งวิธีการนี้จะช่วยลดปัญหาคอขวด แต่การจัดการเกี่ยวกับการล๊อกจะมีความยุ่งยากมากขึ้น เนื่องจากการร้องของการล๊อกและการร้องขอการปลดล๊อกไม่ได้กระทำที่ไซต์เดียว 3. Majority Protocol วิธีการนี้แต่ละไซต์จะจัดการเกี่ยวกับการร้องขอการล๊อกและการปลดล๊อก ของข้อมูล ที่ถูกเก็บอยู่ภายในไซต์นั้น เมื่อทรานแซกชันต้องการล๊อกข้อมูล Q ที่ไม่ได้ทำสำเนาไว้ และถูกเก็บอยู่ที่ไซต์ Si ก็จำทำการส่งสัญญาณร้องขอการล๊อกไปที่ตัวจัดการการล๊อกที่ไซต์ Si ถ้าข้อมูล Q ถูกล๊อกอยู่ในโหมด incompatible การร้องขอจะถูกรอไว้จนกระทั่งสามารถล๊อกได้ และเมื่อตัวจัดการการล๊อกที่ไซต์ Si ตรวจสอบว่าสามารถล๊อกข้อมูลได้แล้วก็จะส่งสัญญาณกลับไปยังไซต์ที่ร้องขอ วิธีการนี้มีข้อดีตรงที่จัดการได้ง่ายคือ มีการส่งสัญญาณการร้องขอล๊อก เพื่อจัดการกับการล๊อก และสัญญาณการขอปลดล๊อกเพียงสัญญาณเดียว อย่างไรก็ตามการจัดการเกี่ยวกับการล๊อกตายจะมีความซับซ้อนมากขึ้นเนื่องจากการร้องขอการล๊อกและการปลดล๊อกไม่ได้กระทำที่ไซต์เดียว 4. Biased Protocol วิธี bias นี้มีพื้นฐานมาจาก majority protocol ซึ่งความแตกต่างอยู่ที่การร้องขอการล๊อกแบบ share ถูกร้องขอมากกว่าการล๊อกแบบ Exclusive ระบบดูแลตัวจัดการการล๊อกในแต่ละไซต์เอง ตัวจัดการแต่ะละตัวจะจัดการการล๊อกสำหรับข้อมูลทุกตัวในเก็บอยู่ในไซต์นั้น การล๊อกแบบ share และแบบ exclusive มีการจัดการที่แตกต่างกันดังนี้ - Shared locks เมื่อทรานแซกชันหนึ่งต้องการล๊อกข้อมูล Q ก็จะทำการร้องขอการล๊อกข้อมูล Q จากตัวจัดการล๊อกเพียงไซต์เดียว ที่มีสำเนาของข้อมูล Q - Exclusive lock เมื่อทรานแซกชันต้องการที่จะล๊อกข้อมูล Q ก็จะทำการร้องขอการล๊อกข้อมูล Q จากตัวจัดการการล๊อก ที่ทุก ๆ ไซต์มีสำเนาของ Q 5. Primary Copy ในกรณีของการทำสำเนาข้อมูล เราสามารถเลือกสำเนาหนึ่งจากหลาย ๆ สำเนาเป็นสำเนาหลัก(primary copy) และกำหนดให้เป็นไซต์หลักของข้อมูล Q เมื่อทรานแซกชันต้องการล๊อกข้อมูล Q ก็จะต้องร้องขอการล๊อกไปที่ไซต์หลักของข้อมูล Q ดังนั้น วิธีการนี้ทำให้สามารถควบคุมสภาวะการทำงานพร้อมกันสำหรับ สำเนาของข้อมูล การดำเนินการในลักษณะนี้สามารถทำได้ง่าย อย่างไรก็ตามถ้าไซต์หลักของข้อมูล Q เกิดล้มเหลว ก็จะไม่สามารถเข้าถึงข้อมูล Q ได้ ทั้งที่ไซต์อื่น ๆ มีการเก็บสำเนาข้อมูล Q ไว้ก็ตาม
หลักการของการทำ timestamp คือการกำหนดค่า timestamp ที่มีค่าไม่ซ้ำกันให้กับแต่ละทรานแซกชัน เพื่อใช้ในการลำดับของการทำทรานแซกชัน ดังนั้นในระบบฐานข้อมูลแบบกระจายสิ่งที่ต้องทำเป็นอันดับแรกคือการกำหนดค่า timestamp ให้กับทรานแซกชันต่าง ๆ ในแต่ละไซต์ ซึ่งก็มีอยู่ 2 วิธีหลัก ๆ ในการกำหนดค่า timestamp ไม่ให้ซ้ำกันคือ การกำหนดแบบศูนย์กลาง และการกำหนดแบบกระจาย ในการกำหนดแบบศูนย์กลาง เราจะกำหนดให้ไซต์หนึ่งเป็นไซต์ศูนย์กลางที่ทำหน้าที่กำหนด timestamp ให้กับไซต์อื่น ๆ โดยการใช้เลขลำดับ หรือเวลาของไซต์ก็ได้ วิธีการกำหนดแบบกระจาย แต่ละไซต์จะกำหนดค่า timestamp ที่ไซต์ของตนเอง โดยใช้เลขลำดับหรือเวลาของไซต์ โดยเราสามารถทำให้ timestamp มีค่าไม่ซ้ำกันในทุก ๆ ไซต์ได้โดยนำไปรวมกับเลขเอกลักษณ์ที่ใช้ระบุไซต์ ซึ่งทำให้ timestamp ที่ได้มีค่าไม่ซ้ำกันอย่างแน่นอน เราพบว่ายังมีปัญหาเกิดขึ้นถ้าไซต์หนึ่งมีกำหนดเลข timestamp เร็วกว่าอีกไซต์หนึ่ง ซึ่งในกรณีนี้ เลขลำดับในไซต์ที่เร็วกว่า จะมีค่ามากกว่าไซต์อื่น ดังนั้นค่า timestamp ทุกค่าที่ถูกกำหนดโดยไซต์ที่เร็วกว่าจะมีค่ามากกว่าเสมอ ดังนั้นเราจึงต้องมีกระบวนการที่จะทำให้เลข timestamp ที่กำหนดขึ้นในแต่ละไซต์ ให้เป็นไปตามความเป็นจริง ในที่นี้เราจะกำหนด logical clock(LCi)ภายในแต่ละไซต์ Si โดย logical clock นี้จะทำหน้าที่เป็นตัวนับที่จะถูกเพิ่มขึ้น หลังจากที่ได้กำหนดค่า timestamp ใหม่ขึ้นมา เพื่อให้แน่ใจว่า logical clock ต่าง ๆ มีความสอดคล้องกัน เราต้องการให้ไซต์ Si เพิ่มค่า logical clock เมื่อไรก็ตามที่ทรานแซกชัน Ti ที่กำหนด timestamp เป็น <x,y> เกิดขึ้น และมีค่า x มีค่ามากกว่าค่า LCi ในกรณีนี้จะทำการเพิ่มค่า LCi เป็น x+1
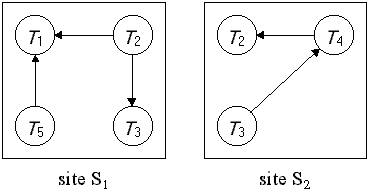
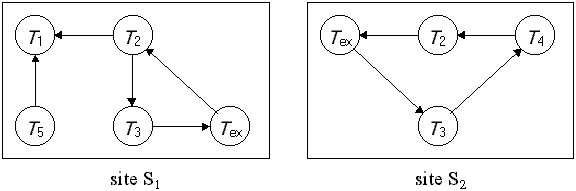
การจัดการกับการล๊อกตายในระบบฐานข้อมูลแบบกระจาย สามารถที่จะนำวิธี deadlock-prevention และวิธี deadlock-detection ที่ใช้กับระบบฐานข้อมูลแบบรวมศูนย์มาปรับใช้ได้ deadlock prevention ทำให้ไม่เกิดการคอย และไม่ต้องทำ rollback ส่วน deadlock detection จะยอมให้เกิดการล๊อกตายก่อน แล้วจึงจัดการกับล๊อกตายนั้นซึ่งปัญหาหลักในระบบฐานข้อมูลแบบกระจายคือการจัดการกับ wait-for graph วิธีการที่ใช้กันทั่วไปคือให้แต่ละไซต์เก็บ local wait-for graph ยกตัวอย่างเช่น เรามีไซต์สองไซต์ แต่ละไซต์จัดการกับ local wait-for graph ของตนเอง จะเห็นว่าทรานแซกชัน T2 และ T3 ปรากฎอยู่ในทั้ง 2 กราฟ ดังรูปที่ 13.8 แสดงให้เห็นว่าทรานแซกชันได้ร้องขอข้อมูลจากทั้งสองไซต์
รูปที่ 13.8 แสดง local wait-for graph local wait-for graph นี้ ถูกสร้างขึ้นมาเพื่อใช้จัดการกับทรานแซกชันภายในไซต์ เมื่อทรานแซกชัน Ti บนไซต์ S1 ต้องการข้อมูลในไซต์ S2 ทรานแซกชัน Ti ก็จะส่งสัญญาณไปให้ไซต์ S2 ถ้าข้อมูลกำลังถูกจัดการอยู่โดย ทรานแซกชัน Tj ด้านของกราฟ Ti à Tj จะถูกเพิ่มเข้าไปใน local wait-for graph ของไซต์ S2 ดังนั้นถ้า local wait-for graph เกิดเป็นวงรอบ ก็หมายความว่าเกิดการล๊อกตายเกิดขึ้น ในทำนองเดียวกันการที่ local wait-for graph ไม่เกิดวงรอบ ก็ไม่ได้หมายความว่าจะไม่เกิดการล๊อกตายเช่นกัน จากตัวอย่างข้างต้น local wait-for graph ในแต่ละไซต์ไม่เกิดวงรอบ แต่เมื่อนำ local wait-for graph ทั้งสองมารวมกันจะพบว่าเกิดลักษณะวงรอบขึ้น ซึ่งจะเกิดการล๊อกตาย ดังรูปที่ 13.9
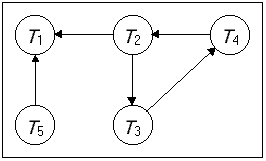
รูปที่ 13.9 แสดงลักษณะการเกิด Global local wait-for graph ในการจัดการกับ wait-for graph ในระบบฐานข้อมูลแบบกระจายมีอยู่หลายวิธี ในที่นี่จะขอกล่าวถึงสองวิธีคือ
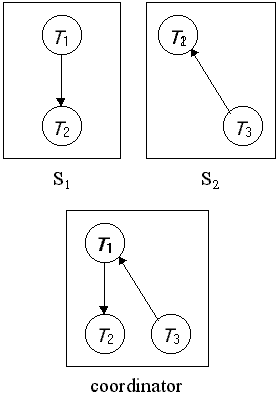
วิธีการแบบรวมศูนย์จะทำการสร้าง global wait-for graph และจัดเก็บไว้ในไซต์เดียว และมีตัวประสานงาน deadlock-detection ทำหน้าที่คอยตรวจสอบการล๊อกตาย และเนื่องจากมีความล่าช้าของการสื่อสารในระบบเครือข่าย global wait-for graph จะถูกสร้างภายใต้เงื่อนไขต่อไปนี้ - เมื่อไรก็ตามที่มีการเพิ่มหรือลบด้านของกราฟ ของ local wait-for graph ใด ๆ - เมื่อเกิดการเปลี่ยนแปลงจำนวนหนึ่งใน local wait-for graph - เมื่อไรก็ตามที่ตัวประสานงานทำการตรวจสอบการการเกิดวงรอบล๊อกตาย เมื่อทำการตรวจสอบการล๊อกตาย ตัวประสานงานก็จะค้นหาวงรอบใน global graph ถ้าพบวงรอบก็จะทำการเลือกทรานแซกชันหนึ่งในวงรอบนั้น เพื่อทำการ rolled back และจะแจ้งกลับไปทุก ๆ ไซต์ โดยเฉพาะทรานแซกชันที่ถูกเลือกเพื่อทำ rolled back จากนั้นจึงทำ roll back ทรานแซกชันที่ถูกเลือกนั้น เราพบว่าแนวทางนี้อาจทำให้เกิดการ rollbacks อย่างไม่จำเป็นได้ ถ้าเป็นไปตามเงื่อนไขดังนี้ - False Cycle อาจจะเกิดขึ้นได้ใน global wait-for graph พิจารณาจากรูปที่ 13.9 สมมุติว่า T2 ได้ปล่อยข้อมูลในไซต์ S1 นั่นคือจะทำการลบของ T1 à T2 ในไซต์ S1 จากนั้นทรานแซกชัน T2 ต้องการใช้ข้อมูลที่ถูกใช้โดยทรานแซกชัน T3 ที่ไซต์ S2 ดังนั้นที่ไซต์ S2 ก็จะทำการเพิ่มโหนด T2 คือ T2 à T3 ถ้าสัญญาณการเพิ่ม T2 à T3 จากไซต์ S2 ไปถึงตัวประสานงานก่อนที่สัญญาณการลบ T1 à T2 ตัวประสานงานจะพบว่าเกิดวงรอบขึ้นคือ T1 à T2 à T3 à T1 ดังนั้นระบบก็จะทำการยกเลิกทรานแซกชัน ที่เกิดการล๊อกตาย แม้ว่าจริง ๆ แล้วจะไม่เกิดการล๊อกตาย - การยกเลิกทรานแซกชันโดยไม่จำเป็น(Unnecessary rollbacks) จะเกิดขึ้นในกรณีที่มีการเกิดการล๊อกตายจริง ๆ และมีการเลือกทรานแซกชันที่จะทำการ rollback ในขณะที่ทรานแซกชันหนึ่งถูกยกเลิกโดยที่ไม่เกี่ยวข้องกับการเกิดการล๊อกตายในกรณี false cycle ยกตัวอย่างเช่น ที่ไซต์ S1 .ในรูป 13.10 ตัดสินใจที่จะยกเลิกทรานแซกชัน T2 และในขณะเดียวกันตัวประสานงานพบว่าเกิดวงรอบ และเลือกที่จะยกเลิกทรานแซกชัน T3 ดังนั้นทรานแซกชัน T2 และ T3 จะถูก rollback ทั้งสองทรานแซกชัน
รูปที่ 13.10 แสดง False Cycle ใน Global local wait-for graph
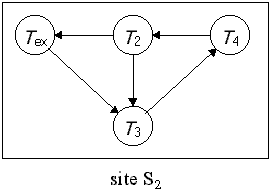
ในการตรวจสอบการล๊อกตายแบบ fully distributed นั้น ตัวควบคุมทุกตัวมีหน้าที่ในการตรวจสอบการล๊อกตายเหมือนกัน ดังนั้นแนวทางนี้ ทุก ๆ ไซต์จะทำการสร้าง wait-for graph ซึ่งแทนส่วนหนึ่งของกราฟทั้งหมด ขึ้นอยู่กับลักษณะการเปลี่ยนแปลงของระบบ ในแนวคิดนี้ ถ้าเกิดการล๊อกตาย จะปรากฎวงรอบในกราฟด้วย แต่ละไซต์จะมี local wait-for graph โดยที่ local wait-for graph นี้จะแตกต่างตาก local wait-for graph ในแนวทางแบบรวมศูนย์ โดยเราจะเพิ่มโหนด Tex เข้าไปใน local wait-for graph อีกโหนดหนึ่ง โดยโหนด Tex นี้จะแสดงทรานแซกชันที่เกิดภายนอกไซต์นั้น ด้านของกราพ Ti à Tex จะแสดงถึง Ti กำลังคอยข้อมูลที่อยู่อีกไซต์หนึ่งที่ถูกใช้งานอยู่โดยทรานแซกชันอื่น ในทำนองเดียวกัน Texà Tj ก็หมายถึงทรานแซกชันในอีกไซต์หนึ่งกำลังคอยการปล่อยข้อมูลของทรานแซกชัน Tj อยู่ พิจารณา wait-for graph รูปที 13.8 โดยเพิ่มโหนด Tex เข้าไปในกราฟทั้งสอง ดังรูปที 13.11
รูปที่ 13.11 แสดง local wait-for graph ถ้า local wait-for graph มีวงรอบโดยที่ไม่รวมโหนด Tex ดังนั้นระบบจะเกิดการล๊อกตาย อย่างไรก็ตาม วงรอบที่มีโหนด Tex มีความหมายว่าอาจจะเกิดการล๊อกตายได้ เพื่อให้เกิดความแน่ใจว่ามีการเกิดการล๊อกตายหรือไม่ เราต้องใช้วิธี distributed deadlock detection algorithm สมมุติว่า local wait-for graph ของไซต์ Si เกิดวงรอบที่มีโหนด Tex วงรอบนี้แสดงได้ในรูปของ Tex à Tk1 à Tk2 à … à Tkn à Tex ซึ่งบอกกับเราว่าทรานแซกชัน Tkn ในไซต์ Si กำลังคอยการเข้าใช้ข้อมูลจากไซต์อื่น กำหนดให้เป็นไซต์ Sj ในการตรวจสอบวงรอบนี้ ไซต์ Si จะส่งสัญญาณ deadlock detection ที่มีข้อมูลเกี่ยวกับการเกิดวงรอบไปให้ไซต์ Sj เมื่อไซต์ Sj ได้รับสัญญาณ deadlock detection มันจะทำการปรับปรุง local wait-for graph ด้วยข้อมูลใหม่ที่ได้รับมาจากไซต์ Si ในขั้นตอนต่อไปจะทำการค้นหาวงรอบที่ไม่มี Tex ใน wait-for graph ที่ได้สร้างใหม่ ถ้ามีอย่างน้อยหนึ่งวงรอบ ก็หมายความว่ามีการล๊อกตายเกิดขึ้น และจะทำการยกเลิกทรานแซกชันตามความเหมาะสม ถ้าพบว่าวงรอบที่เกิดขึ้นมี Tex อยู่ด้วย Sj จะส่งสัญญาณ deadlock detection ไปยังไซต์ที่เหมาะสม Sk ที่ไซต์ Sk ก็จะทำการตรวจสอบการล๊อกตายเหมือนกับที่ได้ทำก่อนหน้านี้ เพื่อให้เกิดความชัดเจนมากยิ่งขึ้น พิจารณา wait-for graph ในรูปที่ 13.11 ในไซต์ S1 Tex à T2 à T3 à Tex เนื่องจาก T3 กำลังคอยที่จะเข้าใช้ขอมูลในไซต์ S2 ไซต์ S1 ก็จะส่งสัญญาณ deadlock detection และข้อมูลการเกิดวงรอบที่เกิดขึ้นไปให้ไซต์ S2 เมื่อไซต์ S2 ได้รับสัญญาณ ก็จะทำการปรับปรุง local wait-for graph ของตนเอง จะได้ wait-for graph ดังรูปที่ 13.12 T2 à T3 à T4 à T2 ซึ่งไม่รวมโหนด Tex ดังนั้นระบบจะอยู่ในสถานะล๊อกตาย ระบบก็จะทำการยกเลิกทรานแซกชันตามความเหมาะสม
รูปที่ 13.12 แสดง local wait-for graph ในทำนองเดียวกันถ้าไซต์ S2 พบว่ามีวงรอบเกิดขึ้นใน local wait-for graph และทำการส่งสัญญาณ deadlock detection ไปให้ไซต์ S1 และในกรณีที่แย่ที่สุด ทั้งสองไซต์ตรวจพบว่ามีวงรอบพร้อมๆ กัน และทำการส่งสัญญาณ deadlock detection พร้อม ๆ กัน ทำให้มีการส่งสัญญาณที่ไม่จำเป็นและข้อมูลที่ใช้ในการปรับปรุง local wait-for graph ทั้งสองไซต์ และทำการค้นหาวงรอบในทั้งสองไซต์ เพื่อลดการส่งสัญญาณในระบบ เราจะกำหนดค่า unique identifier ให้แต่ละทรานแซกชัน Ti แทนด้วย ID (Ti) เมื่อไซต์ Sk พบว่า local wait-for graph เกิดวงรอบที่มีโหนด Tex ในรูปแบบ Tex à Tk1 à Tk2 à … à Tkn à Tex ไซต์ Sk จะส่งสัญญาณ deadlock detection ไปให้ไซต์อื่น ก็ต่อเมื่อ ID (Tkn) < ID (Tk1) นอกนั้นไซต์ Sk ไม่ต้องทำอะไรปล่อยให้เป็นหน้าที่ของไซต์อื่นทำการตรวจสอบการล๊อกตายต่อไป |
|
|
|
|
|
|